One of the most frustrating aspects of the previous model was that even light training took an hour, and the results were far from satisfactory. In this section, we will explore how combining two techniques can significantly speed up network training! The intuitive approach is to start with a higher learning rate and gradually decrease it as training progresses. This makes sense because, at the beginning, we are far from the optimal solution, so we want to take large steps in the right direction. However, as we get closer to the minimum, we need to be more cautious to avoid overshooting. Think of it like taking a train home; once you're near your house, you wouldn't let the train carry you all the way into your living room. The importance of initialization and momentum in deep learning was highlighted in talks and papers by Ilya Sutskever and his colleagues. There, they introduced another useful technique to accelerate deep learning: increasing the momentum parameter during training. In our earlier model, we used fixed values for the learning rate and momentum—0.01 and 0.9, respectively. Now, we'll modify these parameters so that the learning rate decreases linearly over time, while the momentum increases gradually. NeuralNet allows us to update parameters using the on_epoch_finished callback during training. We can pass a function to on_epoch_finished so that it gets executed after each epoch. However, before changing the learning rate and momentum, we must convert them into Theano shared variables. Fortunately, this is straightforward. Import theano def float32(k): Net4 = NeuralNet( The callback function or list we pass needs two arguments when called: nn, which is an instance of NeuralNet, and train_history, which contains the training history. Instead of using a hard-coded function, we’ll use a parameterizable class where we define a call method as our callback. Let's call this class AdjustVariable. The implementation is quite simple: class AdjustVariable(object): def __call__(self, nn, train_history): Now, let’s put these changes together and prepare for training the network: Net4 = NeuralNet( X, y = load2d() with open('net4.pickle', 'wb') as f: We will train two networks: net4 does not use our FlipBatchIterator, while net5 does. Otherwise, they are identical. Here is the result for net4: Epoch | Train loss | Valid loss | Train / Val Great! Training is faster now. Before adjusting the learning rate and momentum, the training error at 500 and 1000 epochs was much higher than in the previous net2. This time, the generalization seems to plateau around 750 epochs, but the training continues for longer periods. What about net5, which uses data augmentation? Epoch | Train loss | Valid loss | Train / Val Once again, we see faster training compared to net3, and better results overall. After 1000 iterations, the performance is already better than what net3 achieved after 3000 iterations. Additionally, models trained with data augmentation show about a 10% improvement over those without it. Dropout Tips In addition to adjusting the learning rate and momentum, we also explored the use of dropout—a regularization technique that randomly deactivates neurons during training to prevent overfitting. Dropout helps improve the model's ability to generalize by forcing the network to learn redundant features. While we didn’t implement it here, it’s a powerful tool worth considering for future experiments.
Round Tapered pole are furnished with anchor bolts featuring zinc-plated double nuts and washers. Galvanized anchor bolts are optional.
Yixing Futao Metal Structural Unit Co. Ltd. is com manded of Jiangsu Futao Group.
Round Taper Steel Pole,Round Taper Galvanized Steel Pole,Round Tapered Pole JIANGSU XINJINLEI STEEL INDUSTRY CO.,LTD , https://www.chinasteelpole.com
return np.cast['float32'](k)
# ...
update_learning_rate=theano.shared(float32(0.03)),
update_momentum=theano.shared(float32(0.9)),
# ...
)
def __init__(self, name, start=0.03, stop=0.001):
self.name = name
self.start, self.stop = start, stop
self.ls = None
if self.ls is None:
self.ls = np.linspace(self.start, self.stop, nn.max_epochs)
epoch = train_history[-1]['epoch']
new_value = float32(self.ls[epoch - 1])
getattr(nn, self.name).set_value(new_value)
# ...
update_learning_rate=theano.shared(float32(0.03)),
update_momentum=theano.shared(float32(0.9)),
# ...
regression=True,
# batch_iterator_train=FlipBatchIterator(batch_size=128),
on_epoch_finished=[
AdjustVariable('update_learning_rate', start=0.03, stop=0.0001),
AdjustVariable('update_momentum', start=0.9, stop=0.999),
],
max_epochs=3000,
verbose=1,
)
Net4.fit(X, y)
pickle.dump(net4, f, -1)
--------|--------------|--------------|-----------
50 | 0.004216 | 0.003996 | 1.055011
100 | 0.003533 | 0.003382 | 1.044791
250 | 0.001557 | 0.001781 | 0.874249
500 | 0.000915 | 0.001433 | 0.638702
750 | 0.000653 | 0.001355 | 0.481806
1000 | 0.000496 | 0.001387 | 0.357917
--------|--------------|--------------|-----------
50 | 0.004317 | 0.004081 | 1.057609
100 | 0.003756 | 0.003535 | 1.062619
250 | 0.001765 | 0.001845 | 0.956560
500 | 0.001135 | 0.001437 | 0.790225
750 | 0.000878 | 0.001313 | 0.668903
1000 | 0.000705 | 0.001260 | 0.559591
1500 | 0.000492 | 0.001199 | 0.410526
2000 | 0.000373 | 0.001184 | 0.315353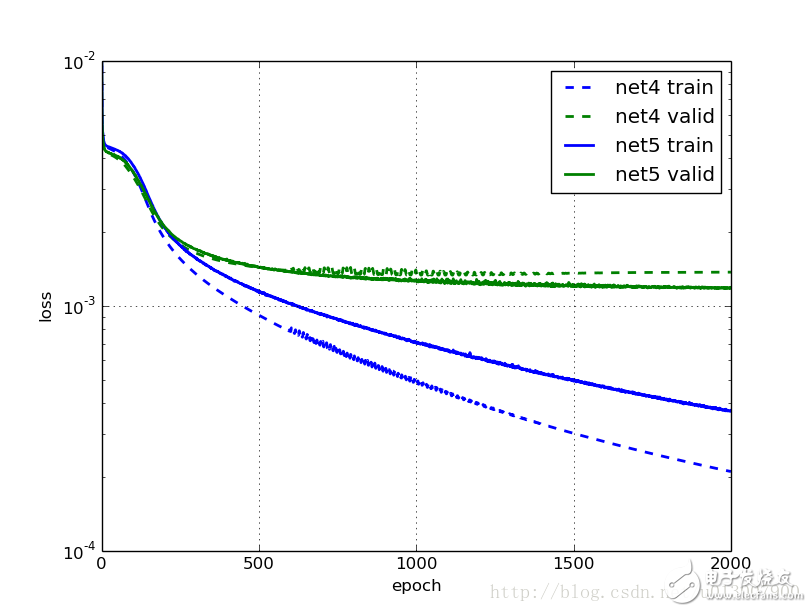
It is located in the beach of scenic and rich Taihu Yixing with good transport service.
The company is well equipped with advanced manufacturing facilities.
We own a large-sized numerical control hydraulic pressure folding machine with once folding length 16,000mm and the thickness 2-25mm.
We also equipped with a series of numerical control conveyor systems of flattening, cutting, folding and auto-welding, we could manufacture all kinds of steel poles and steel towers.
Our main products: high & medium mast lighting, road lighting, power poles, sight lamps, courtyard lamps, lawn lamps, traffic signal poles, monitor poles, microwave communication poles, etc. Our manufacturing process has been ISO9001 certified and we were honored with the title of the AAA grade certificate of goodwill.
Presently 95% of our products are far exported to Europe, America, Middle East, and Southeast Asia, and have enjoyed great reputation from our customers.
So we know the demand of different countries and different customers.
We are greatly honored to invite you to visit our factory and cheerfully look forward to cooperating with you.