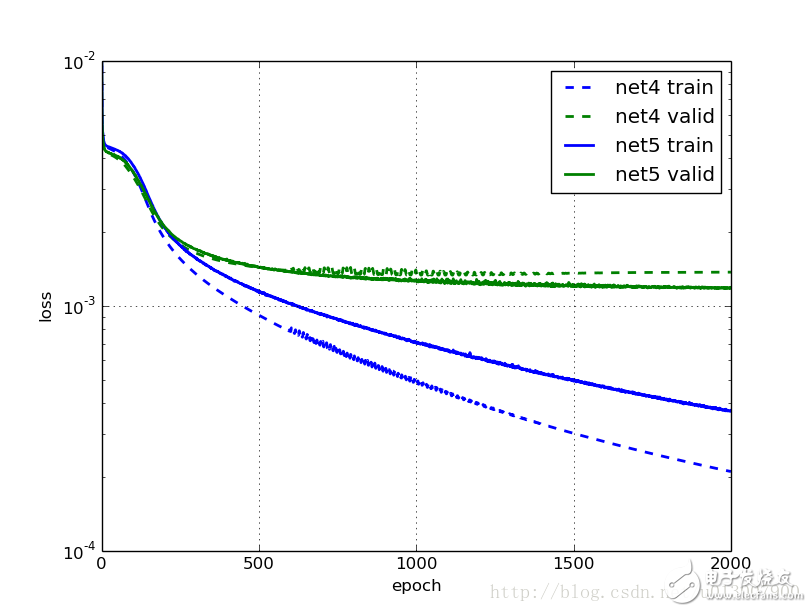
One of the most frustrating aspects of the previous model was that even light training took an hour, and the results weren't very satisfying. In this section, we'll explore how combining two techniques can significantly speed up the training process of a neural network! An intuitive approach is to start with a higher learning rate at the beginning of training and gradually decrease it as the number of iterations increases. This makes sense because early on, you're far from the optimal solution, so taking larger steps in the right direction helps. However, as you get closer to the minimum, smaller steps are better to avoid overshooting. Think of it like riding a train home—you don’t want to let the train drive into your house; instead, you walk the last few steps. The importance of initialization and momentum in deep learning was highlighted in talks and papers by Ilya Sutskever and his colleagues. There, they introduced another useful technique for improving deep learning: increasing the momentum parameter during training. This helps the optimization process converge more smoothly and efficiently. In our previous model, we used fixed values for the learning rate (0.01) and momentum (0.9). To improve performance, we will now make the learning rate decrease linearly over time while increasing the momentum. This dynamic adjustment allows the model to explore the loss landscape more effectively early on and fine-tune its parameters later. NeuralNet provides a way to update parameters using the `on_epoch_finished` callback during training. We can pass a custom function to this callback so that it runs after each epoch. Before changing the learning rate and momentum, these parameters need to be converted into Theano shared variables. Fortunately, this is straightforward. Importing Theano and defining a helper function for float32 conversion: ```python def float32(k): return np.cast['float32'](k) ``` Then, initializing the learning rate and momentum as shared variables: ```python Net4 = NeuralNet( # ... update_learning_rate=theano.shared(float32(0.03)), update_momentum=theano.shared(float32(0.9)), # ... ) ``` The callback function or list needs two arguments: `nn`, which is an instance of `NeuralNet`, and `train_history`, which contains the training history. Instead of hardcoding the logic, we define a class that can dynamically adjust the learning rate and momentum based on the current epoch. Here’s the implementation of the `AdjustVariable` class: ```python class AdjustVariable(object): def __init__(self, name, start=0.03, stop=0.001): self.name = name self.start, self.stop = start, stop self.ls = None def __call__(self, nn, train_history): if self.ls is None: self.ls = np.linspace(self.start, self.stop, nn.max_epochs) epoch = train_history[-1]['epoch'] new_value = float32(self.ls[epoch - 1]) getattr(nn, self.name).set_value(new_value) ``` Now, putting it all together and preparing for training: ```python Net4 = NeuralNet( # ... update_learning_rate=theano.shared(float32(0.03)), update_momentum=theano.shared(float32(0.9)), # ... regressive=True, on_epoch_finished=[ AdjustVariable('update_learning_rate', start=0.03, stop=0.0001), AdjustVariable('update_momentum', start=0.9, stop=0.999), ], max_epochs=3000, verbose=1, ) ``` After training, we save the model: ```python X, y = load2d() Net4.fit(X, y) with open('net4.pickle', 'wb') as f: pickle.dump(net4, f, -1) ``` We trained two models: net4 without data augmentation and net5 with it. Otherwise, they were identical. Here’s the training progress for net4: Epoch | Train Loss | Valid Loss | Train/Val ------|------------|------------|--------- 50 | 0.004216 | 0.003996 | 1.055011 100 | 0.003533 | 0.003382 | 1.044791 250 | 0.001557 | 0.001781 | 0.874249 500 | 0.000915 | 0.001433 | 0.638702 750 | 0.000653 | 0.001355 | 0.481806 1000 | 0.000496 | 0.001387 | 0.357917 Great! Training is much faster now. Compared to the previous net2, the training error at 500 and 1000 epochs is significantly lower. However, the generalization seems to plateau around 750 epochs, indicating that further training may not yield significant improvements. What about net5, which uses data augmentation? Epoch | Train Loss | Valid Loss | Train/Val ------|------------|------------|--------- 50 | 0.004317 | 0.004081 | 1.057609 100 | 0.003756 | 0.003535 | 1.062619 250 | 0.001765 | 0.001845 | 0.956560 500 | 0.001135 | 0.001437 | 0.790225 750 | 0.000878 | 0.001313 | 0.668903 1000 | 0.000705 | 0.001260 | 0.559591 1500 | 0.000492 | 0.001199 | 0.410526 2000 | 0.000373 | 0.001184 | 0.315353 Again, training is faster than net3, and the results are better. After 1000 epochs, the performance is already better than what net3 achieved after 3000. Moreover, models trained with data augmentation show about a 10% improvement over those without it. Dropout
In order to meet the individual requirements of the clients, we offer an extensive range of tubular steel poles and tubular poles that are acclaimed among the clients for durable standards and exceptional finishing. We offer them in standard sizes and durable in nature. Steel Tubular Poles are corrosion resistant in nature and is delivered in well-defined time frame.
1.Shape:Conoid ,Multi-pyramidal,Columniform,polygonal or conical
2.Material:steel plate.stainless steel compound plate,stainless steel plate,ect.(anticorrosion treatment with hot galvanization,also color polyester power could be coated on the surface)
High strength low alloy steel Q235,Q345,GR65,GR50 to ensure the mechanical properity of microelement in order to ensure the quality of galvanization (other materials are also avaliable on request)
3.Jointing of pole with insert mode,innerflange mode,face to face joint mode
4.Design of pole :against earthquake of 8 grade ,aganist wind pressure of 160
5.Minimum yield strength:355 mpa
6.Minimum ultimate tensile strength :490 mpa
7.Max ultimate tensilestrength:620 mpa
8.Certificate:ISO9001-2000
9.Length:Within 14m once forming without slip joint
10.Welding:It has past flaw testing.Internal and external double welding makes the welding beautiful in shape
11:Packages:Our poles as normal cover by Mat or straw bale at the top and bottom ,anyway also can following by client required , each 40HC or OT can loading how many pcs will calculation base on the client actually specification and data
Our lighting equipment are made from quality sheet from bending,forming,automatic welding and hot galvanization.We can reach one-run machining length of 14m,and can bend sheet thickness up to 25mm.We adopt advanced welding procedures ,automatically weld main joints and reach rank-II welding quality.
Steel Tubular Pole,Galvanized Tubular Steel,Steel Tubular Pole Tower JIANGSU XINJINLEI STEEL INDUSTRY CO.,LTD , https://www.chinasteelpole.com